rust异步编程
如何理解异步
在开始编程之前,我们先了解几个异步编程中相关的概念:
-
并发和并行
-
同步和异步
-
阻塞和非阻塞
并发和并行
并发
当有多线程在操作时,如果系统只有一个cpu,那么实际上不可能同时运行一个及以上的线程,在这种情况下,cpu会以一定的时间周期来划分时间片段,再将各个时间片段分配给线程使用,在一个时间段中的线程运行时,其他的没有获取时间段的线程处于挂起状态。只要划分的时间片段足够小,看上去好像每个线程都在持续的占用cpu的资源,这种方式称为并发。
并行
同样是多个线程在操作,但是系统有多个cpu,每个线程能够独享一个cpu的全部时间,各个线程的任务可以同时进行。
通常并行情况是不存在的,因此我们大多数的情况下都讨论的是并发问题。
下面一张图通俗易懂的描述了并发和并行的区别:
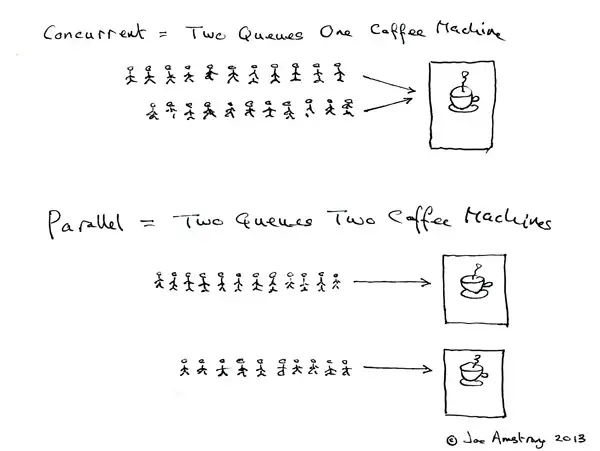
并发是两个队列同时使用一台咖啡机,并行时两个队列同时使用两个咖啡机,如果串行,一个队列使用一台咖啡机,那么哪怕前面那个人便秘了去厕所呆半天,后面的人也只能死等着他回来才能去接咖啡,这效率无疑是最低的。
并发和并行以及多线程的关系
并发和并行都能够是单线程或者是多线程的,重点是这些线程能不能同时被多个cpu执行,如果可以就是并行,如果需要交替使用cpu的资源就是并发。
同步和异步
同步
同步是最常见的情况,我们一般写的代码都是同步的代码,如下:
fn a(){
b()
//...something else
}
fn b(){
...
}a函数调用b函数,在b函数返回之前,a函数都不会继续往下执行,也就是说,a函数必须等待b函数执行完才能继续往下执行:
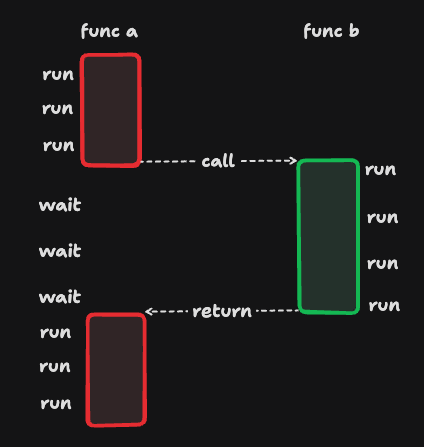
在等待b函数执行的期间,a函数什么都做不了,这就是典型的同步的场景。
在上面的情况下,函数a和函数b运行在同一个线程中,这是最常见的情况,但是即使是运行在不同线程中的函数,也可以是同步的,比如磁盘文件读取:
read(file, buf);这就是阻塞式I/O,在read函数返回前程序是无法继续向前推进的
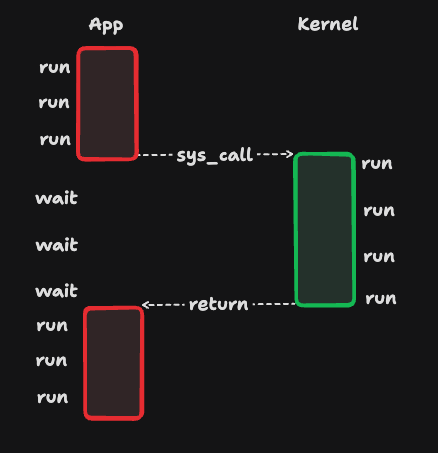
只有当read函数返回后程序才可以被继续执行。注意,和上面的同步调用不同的是,函数和被调函数运行在不同的线程中。
结论:
同步调用与函数和被调函数是否在同一个线程中是没有关系的,同步模型最好理解,但是这样带来的代价就是同步代码效率低,因为任务无法同时执行。
接着让我们来看看异步调用。
异步
一般来说,异步调用总是和i/o操作等耗时较高的任务如影随形,像磁盘文件的读写,网络数据的收发,数据库操作等等。
在read函数的同步调用方式下,在read函数读取完之前调用方是无法继续向前推进的,但是如果read函数可以异步进行调用,即使文件没有读取完毕,函数也能立即返回:
read(file, buff);
// read函数立即返回
// 不会阻塞当前程序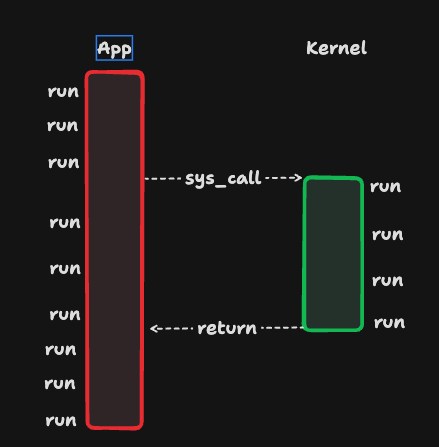
可以看到,在异步这种调用方式下,调用方不会被阻塞,函数调用完成后可以立即执行接下来的程序。这时异步的重点就在于调用方接下来的程序执行可以和文件读取同时进行,从上图中我们也能看出这一点,这就是异步的高效之处。但是,请注意,异步调用对于程序员来说在理解上是一种负担,代码编写上更是一种负担,总的来说,上帝在为你打开一扇门的时候会适当的关上一扇窗户。有的同学可能会问,在同步调用下,调用方不再继续执行而是暂停等待,被调函数执行完后很自然的就是调用方继续执行,那么异步调用下调用方怎知道被调函数是否执行完成呢?这就分为了两种情况:
1、调用方不需要关心函数调用的执行结果
2、调用方需要关心调用的执行结果。
第一种情况比较简单,第二种方式就比较有趣了,主要有两种实现方式:
- 通知机制,也就是当前任务执行完毕后通过发送信号来通知调用方任务执行完毕。这里实现信号的方式有很多种,比如Linux中的signal或者信号量机制。
- callback函数。
同步vs异步举例
我们以常见的Web服务来举例说明这一问题。一般来说Web Server接收到用户请求后会有一些典型的处理逻辑,最常见的就是数据库查询(当然,你也可以把这里的数据库查询换成其它I/O操作,比如磁盘读取、网络通信等),在这里我们假定处理一次用户请求需要经过步骤A、B、C,然后读取数据库,数据库读取完成后需要经过步骤D、E、F,就像这样:
# 处理一次用户请求需要经过的步骤:
A;
B;
C;
数据库读取;
D;
E;
F;其中步骤A, B, C和D, E, F不需要任何i/o操作,也就是说涉及i/o操作的只有数据库查询操作。一般来说这样的web server有两个经典的线程,主线程和数据库线程。
// 主线程
main_thread() {
A;
B;
C;
发送数据库查询请求;
D;
E;
F;
}
// 数据库线程
DataBase_thread() {
while(1) {
处理数据库读取请求;
返回结果;
}
}这就是最为典型的同步方法,主线程在发出数据库查询请求后就会被阻塞而暂停运行,直到数据库查询完毕后面的D、E、F才可以继续运行,就像这样:
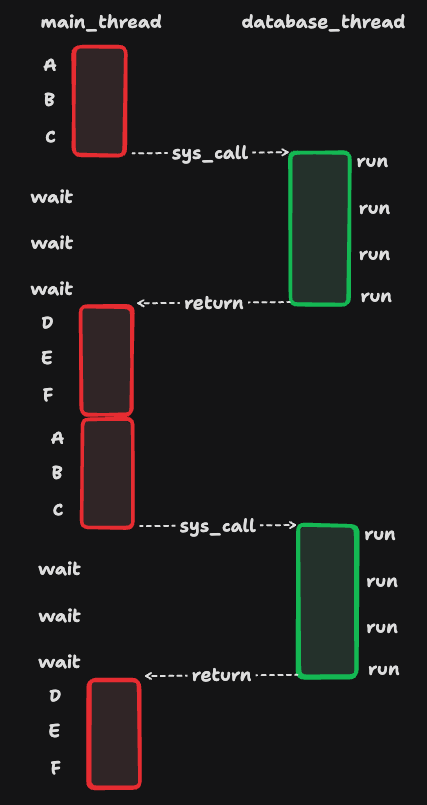
从图中我们可以看到,主线程中会有“空隙”,这个空隙就是主线程的“休闲时光”,主线程在这段休闲时光中需要等待数据库查询完成才能继续后续处理流程。
在异步这种实现方案下主线程根本不去等待数据库是否查询完成,而是发送完数据库读写请求后直接处理下一个请求。
一个请求经过A, B, C, 数据库查询, D, E, F这七个步骤,如果主线程在完成A, B, C, 数据库查询后直接进行处理下一个请求,那么上一个请求的D, E, F怎么办呢?
这里有两种需要讨论的情况:
1、调用方不关心函数调用的结果
主线程根本不关心数据库查询的结果,数据库查询完毕后自动处理D, E, F三个步骤:
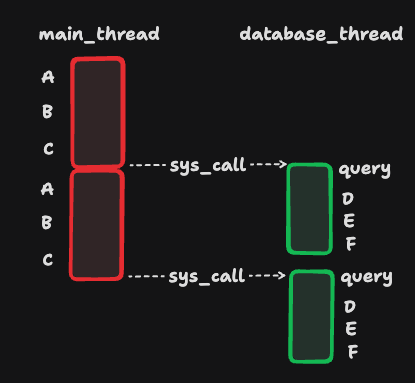
一个请求需要经过七个处理步骤,我们从图中可以看出,A, B, C三个步骤是在主线程中执行的,后四个步骤是在数据库线程中完成的,那么数据库线程是怎么知道在查询完数据库过后要去执行D, E, F 这三个步骤的?===> 通过回调函数进行:
function callBack(){
D()
E()
F()
}主线程发送数据库查询请求的时候将该函数作为参数一并进行传递即可:
function dbQuery(request, callBack){
//query database
//call callback handler
callBack()
}2、主线程关心数据库操作的结果
数据库线程需要将查询结果通过通知机制发送给主线程,主线程在接收到消息后继续处理上一个请求的后半部分,就像这样:
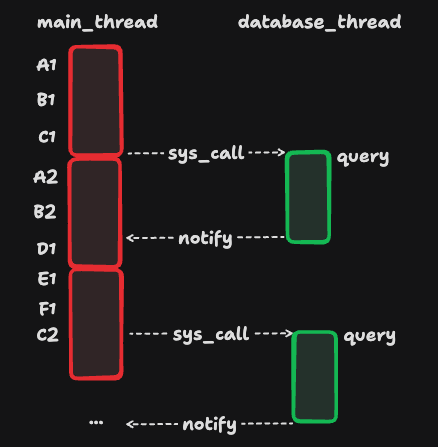
从这里我们可以看到,ABCDEF几个步骤全部在主线中处理,同时主线程同样也没有了“休闲时光”,只不过在这种情况下数据库线程是比较清闲的,从这里并没有上一种方法高效,但是依然要比同步模式下要高效。最后需要注意的是,并不是所有的情况下异步都一定比同步高效,还需要结合具体业务以及IO的复杂度具体情况具体分析。
阻塞和非阻塞
在通信层面,阻塞和非阻塞 = 同步和异步。
更详细解释可参考:https://www.zhihu.com/question/19732473
rust中的异步
async和多线程都可以提供给我们并发编程的能力,但是两者有很大的区别。
- async更适合于i/o密集型的任务,因为大部分时间线程处于空闲状态,如果使用多线程,那线程大量时间会处于无所事事的状态,并且会有很大的线程上下文切换的开销。
- 对于长时间运行的 CPU 密集型任务,例如并行计算,使用线程将更有优势。 这种密集任务往往会让所在的线程持续运行,任何不必要的线程切换都会带来性能损耗,因此高并发反而在此时成为了一种多余
但是async也有缺点,原因是编译器会为async函数生成状态机,然后将整个运行时打包进来,这会造成我们编译出的二进制可执行文件体积显著增大。
若大家使用 tokio,那 CPU 密集的任务尤其需要用线程的方式去处理,例如使用
spawn_blocking创建一个阻塞的线程去完成相应 CPU 密集任务。至于具体的原因,不仅是上文说到的那些,还有一个是:tokio 是协作式的调度器,如果某个 CPU 密集的异步任务是通过 tokio 创建的,那理论上来说,该异步任务需要跟其它的异步任务交错执行,最终大家都得到了执行,皆大欢喜。但实际情况是,CPU 密集的任务很可能会一直霸占着 CPU,此时 tokio 的调度方式决定了该任务会一直被执行,这意味着,其它的异步任务无法得到执行的机会,最终这些任务都会因为得不到资源而饿死。
而使用
spawn_blocking后,会创建一个单独的 OS 线程,该线程并不会被 tokio 所调度( 被 OS 所调度 ),因此它所执行的 CPU 密集任务也不会导致 tokio 调度的那些异步任务被饿死
- 有大量
IO任务需要并发运行时,选async模型 - 有部分
IO任务需要并发运行时,选多线程,如果想要降低线程创建和销毁的开销,可以使用线程池 - 有大量
CPU密集任务需要并行运行时,例如并行计算,选多线程模型,且让线程数等于或者稍大于CPU核心数 - 无所谓时,统一选多线程
async 和多线程的性能对比:
| 操作 | async | 线程 |
|---|---|---|
| 创建 | 0.3 微秒 | 17 微秒 |
| 线程切换 | 0.2 微秒 | 1.7 微秒 |
可以看出,async 在线程切换的开销显著低于多线程,对于 IO 密集的场景,这种性能开销累计下来会非常可怕!
举一个例子:并发下载一个文件:
- 使用多线程
fn get_two_sites() {
// 创建两个新线程执行任务
let thread_one = thread::spawn(|| download("https://course.rs"));
let thread_two = thread::spawn(|| download("https://fancy.rs"));
// 等待两个线程的完成
thread_one.join().expect("thread one panicked");
thread_two.join().expect("thread two panicked");
}如果是在小项目中简单的下载文件,上面的代码是没问题的,但是如果下载文件的请求很多的情况下,一个线程执行一个下载任务的模型就太奢侈臃肿了,我们可以使用async来实现:
async fn get_two_sites_async() {
// 创建两个不同的`future`,你可以把`future`理解为未来某个时刻会被执行的计划任务
// 当两个`future`被同时执行后,它们将并发的去下载目标页面
let future_one = download_async("https://www.foo.com");
let future_two = download_async("https://www.bar.com");
// 同时运行两个`future`,直至完成
join!(future_one, future_two);
}async/await入门
async/.await 是 Rust 内置的语言特性,可以让我们用同步的方式去编写异步的代码。
通过 async 标记的语法块会被转换成实现了Future特征的状态机。 与同步调用阻塞当前线程不同,当Future执行并遇到阻塞时,它会让出当前线程的控制权,这样其它的Future就可以在该线程中运行,这种方式完全不会导致当前线程的阻塞。
使用async
首先使用async语法来创建一个异步函数:
async fn say_hi() {
println!("gogogo!")
}
fn main() {
say_hi();
}需要注意,异步函数的返回值是一个 Future,若直接调用该函数,不会输出任何结果,因为 Future 还未被执行。
那么我们如何调用这个函数呢?
- block_on
use futures::executor::block_on;
async fn say_hi() {
println!("gogogo!")
}
fn main() {
let future = say_hi();
block_on(future)
}block_on会等待其中所有的future完成。
- await
上面的代码使用block_on这个执行器等待所有的future完成,让代码看上去就像是同步代码,但是如果我们需要在async fn中调用另一个async fn呢?例如下面的情况:
use futures::executor::block_on;
async fn hello_world() {
hello_cat();
println!("hello, world!");
}
async fn hello_cat() {
println!("hello, kitty!");
}
fn main() {
let future = hello_world();
block_on(future);
}编辑器会报错:
➜ cargo run
Compiling exercise v0.1.0 (/Users/chenzilong/workspace/rust-master/exercise)
warning: unused implementer of `futures::Future` that must be used
--> src/main.rs:4:5
|
4 | hello_cat();
| ^^^^^^^^^^^
|
= note: futures do nothing unless you `.await` or poll them
= note: `#[warn(unused_must_use)]` on by default
warning: `exercise` (bin "exercise") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.11s
Running `target/debug/exercise`
hello, world!可见hello_cat这个异步函数是没有被调用的。
有两种解决办法:使用.await语法或者对Future进行轮询(poll)
后者比较复杂,我们先用.await来解决这个问题:
use futures::executor::block_on;
async fn hello_world() {
hello_cat().await;
println!("hello, world!");
}
async fn hello_cat() {
println!("hello, kitty!");
}
fn main() {
let future = hello_world();
block_on(future);
}输出正常了。
但是与block_on不同,.await并不会阻塞当前的线程,而是异步的等待Future A的完成,在等待的过程中,该线程还可以继续执行其它的Future B,最终实现了并发处理的效果。
一个例子
如果不使用.await的话,可能会有下面的效果:
use futures::executor::block_on;
struct Song {
author: String,
name: String,
}
async fn learn_song() -> Song {
Song {
author: "周杰伦".to_string(),
name: String::from("《菊花台》"),
}
}
async fn sing_song(song: Song) {
println!(
"给大家献上一首{}的{} ~ {}",
song.author, song.name, "菊花残,满地伤~ ~"
);
}
async fn dance() {
println!("唱到情深处,身体不由自主的动了起来~ ~");
}
fn main() {
let song = block_on(learn_song());
block_on(sing_song(song));
block_on(dance());
}它的性能何在?需要通过连续三次阻塞去等待三个任务的完成,一次只能做一件事,实际上我们可以载歌载舞啊:
use futures::executor::block_on;
struct Song {
author: String,
name: String,
}
async fn learn_song() -> Song {
Song {
author: "曲婉婷".to_string(),
name: String::from("《我的歌声里》"),
}
}
async fn sing_song(song: Song) {
println!("sing song: {} - {}", song.author, song.name);
}
async fn dance() {
println!("dance");
}
async fn learn_and_sing() {
let song = learn_song().await;
sing_song(song).await;
}
async fn async_main() {
let f1 = learn_and_sing();
let f2 = dance();
// `join!`可以并发的处理和等待多个`Future`,若`learn_and_sing Future`被阻塞,那`dance Future`可以拿过线程的所有权继续执行。若`dance`也变成阻塞状态,那`learn_and_sing`又可以再次拿回线程所有权,继续执行。
// 若两个都被阻塞,那么`async main`会变成阻塞状态,然后让出线程所有权,并将其交给`main`函数中的`block_on`执行器
futures::join!(f1, f2);
}
fn main() {
block_on(async_main());
}Pin和Unpin
在 Rust 中,所有的类型可以分为两类:
- 类型的值可以在内存中安全地被移动,例如数值、字符串、布尔值、结构体、枚举,总之你能想到的几乎所有类型都可以落入到此范畴内
- 自引用类型,大魔王来了,大家快跑,在之前章节我们已经见识过它的厉害
下面就是一个自引用类型
struct SelfRef {
value: String,
pointer_to_value: *mut String,
}在上面的结构体中,pointer_to_value 是一个裸指针,指向第一个字段 value 持有的字符串 String 。很简单对吧?现在考虑一个情况, 若String 被移动了怎么办?
此时一个致命的问题就出现了:新的字符串的内存地址变了,而 pointer_to_value 依然指向之前的地址,一个重大 bug 就出现了!
灾难发生,英雄在哪?只见 Pin 闪亮登场,它可以防止一个类型在内存中被移动。
深入理解pin
用下面一个例子来帮助我们理解Pin
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
}
impl Test {
fn new(a: &str) -> Self {
Self {
a: String::from(a),
b: std::ptr::null(),
}
}
fn init(&mut self) {
let self_ref: *const String = &self.a;
self.b = self_ref;
}
fn a(&self) -> &str {
&self.a
}
fn b(&self) -> &String {
assert!(
!self.b.is_null(),
"Test::b called without Test::init being called first"
);
unsafe { &*self.b }
}
}如果不移动任何值,程序输出正常:
fn main() {
let mut test1 = Test::new("test1");
test1.init();
let mut test2 = Test::new("test2");
test2.init();
println!("a: {}, b: {}", test1.a(), test1.b());
println!("a: {}, b: {}", test2.a(), test2.b());
}
// a: test1 b: test1
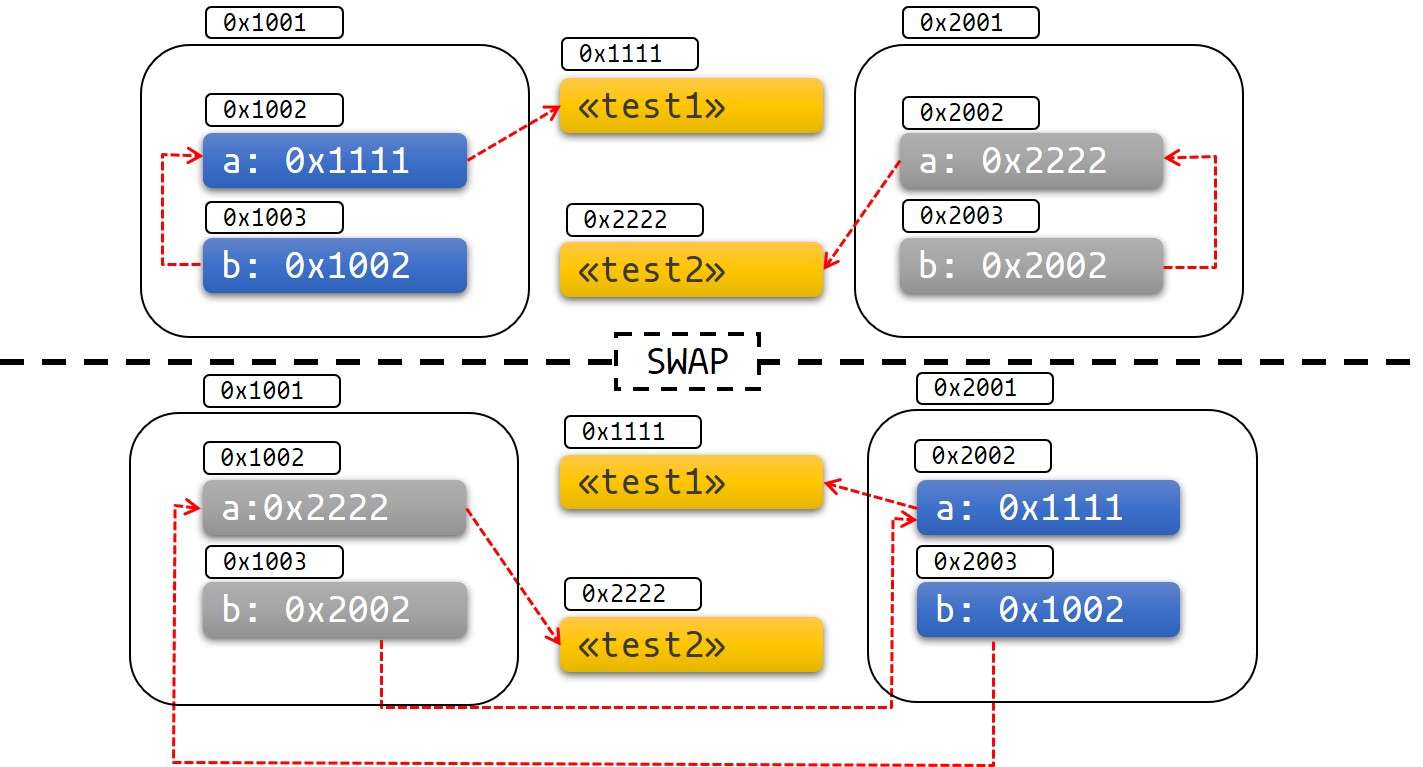
// a: test2 b: test2如果我们尝试去移动值呢,看看结果:
fn main() {
let mut test1 = Test::new("test1");
test1.init();
let mut test2 = Test::new("test2");
test2.init();
println!("a: {}, b: {}", test1.a(), test1.b());
std::mem::swap(&mut test1,&mut test2);
println!("a: {}, b: {}", test2.a(), test2.b());
}
// a: test1 b: test1
// a: test1 b: test2rust圣经上的一张图可以很好的说明产生这种结果的原因:
Pin在实践中的运用
将值固定在栈上
改造之前的例子,我们使用pin来解决指针指向的数据被移动的问题:
use std::{marker::PhantomPinned, pin::Pin};
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
_marker: PhantomPinned,
}
impl Test {
fn new(a: &str) -> Self {
Self {
a: String::from(a),
b: std::ptr::null(),
//使用这么标记来让我们的类型自动实现特征!Unpin
_marker: PhantomPinned,
}
}
fn init(self: Pin<&mut Self>) {
let self_ptr: *const String = &self.a;
let this = unsafe { self.get_unchecked_mut() };
this.b = self_ptr;
}
fn a(&self) -> &str {
&self.a
}
fn b(&self) -> &String {
assert!(
!self.b.is_null(),
"Test::b called without Test::init being called first"
);
unsafe { &*self.b }
}
}一旦类型实现了 !Unpin ,那将它的值固定到栈( stack )上就是不安全的行为,因此在代码中我们使用了 unsafe 语句块来进行处理
不安全的原因:当一个类型实现了 !Unpin,意味着它不能被安全地移动。
如果一个类型被固定到栈上,意味着它的内存地址是固定的,不会发生移动。这可能会导致以下问题:
- 悬垂指针:如果一个类型被固定到栈上,然后在其有效范围之外继续使用指向它的指针,那么这个指针将成为悬垂指针。当尝试使用悬垂指针时,会导致未定义行为。
- 内存泄漏:如果一个类型被固定到栈上,但在其有效范围之外无法释放,那么这个类型的内存将无法被回收,从而导致内存泄漏。
此时,再去尝试移动被固定的值,就会导致编译错误:
fn main() {
// 此时的`test1`可以被安全的移动
let mut test1 = Test::new("test1");
// 新的`test1`由于使用了`Pin`,因此无法再被移动,这里的声明会将之前的`test1`遮蔽掉(shadow)
let mut test1 = unsafe { Pin::new_unchecked(&mut test1) };
Test::init(test1.as_mut());
let mut test2 = Test::new("test2");
let mut test2 = unsafe { Pin::new_unchecked(&mut test2) };
Test::init(test2.as_mut());
println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref()));
std::mem::swap(test1.get_mut(), test2.get_mut());
println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref()));
}一个常见的错误就是忘记去遮蔽( shadow )初始的变量,因为你可以
drop掉Pin,然后在&'a mut T结束后去移动数据:fn main() { let mut test1 = Test::new("test1"); let mut test1_pin = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1_pin.as_mut()); drop(test1_pin); println!(r#"test1.b points to "test1": {:?}..."#, test1.b); let mut test2 = Test::new("test2"); mem::swap(&mut test1, &mut test2); println!("... and now it points nowhere: {:?}", test1.b); }
将值固定到堆上
use std::marker::PhantomPinned;
use std::pin::Pin;
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
_marker: PhantomPinned,
}
impl Test {
fn new(txt: &str) -> Pin<Box<Self>> {
let t = Test {
a: String::from(txt),
b: std::ptr::null(),
_marker: PhantomPinned,
};
let mut boxed = Box::pin(t);
let self_ptr: *const String = &boxed.as_ref().a;
unsafe { boxed.as_mut().get_unchecked_mut().b = self_ptr };
boxed
}
fn a(self: Pin<&Self>) -> &str {
&self.get_ref().a
}
fn b(self: Pin<&Self>) -> &String {
unsafe { &*(self.b) }
}
}
pub fn main() {
let test1 = Test::new("test1");
let test2 = Test::new("test2");
println!("a: {}, b: {}", test1.as_ref().a(), test1.as_ref().b());
println!("a: {}, b: {}", test2.as_ref().a(), test2.as_ref().b());
}将固定住的Future变成Unpin
async 函数返回的 Future 默认就是 !Unpin 的。
但是,在实际应用中,一些函数会要求它们处理的 Future 是 Unpin 的,此时,若你使用的 Future 是 !Unpin 的,必须要使用以下的方法先将 Future 进行固定:
Box::pin, 创建一个Pin<Box<T>>Pin<Box<T>>::as_mut(), 创建一个Pin<&mut T>
固定后获得的 Pin<Box<T>> 和 Pin<&mut T> 既可以用于 Future ,又会自动实现 Unpin。
我们也可以使用
pin_utils的pin_utils::pin_mut!,创建一个Pin<&mut T>use pin_utils::pin_mut; // `pin_utils` 可以在crates.io中找到 // 函数的参数是一个`Future`,但是要求该`Future`实现`Unpin` fn execute_unpin_future(x: impl Future<Output = ()> + Unpin) { /* ... */ } let fut = async { /* ... */ }; // 下面代码报错: 默认情况下,`fut` 实现的是`!Unpin`,并没有实现`Unpin` // execute_unpin_future(fut); // 使用`Box`进行固定 let fut = async { /* ... */ }; let fut = Box::pin(fut); execute_unpin_future(fut); // OK // 使用`pin_mut!`进行固定 let fut = async { /* ... */ }; pin_mut!(fut); execute_unpin_future(fut); // OK
async的生命周期
async fn如果拥有引用类型的参数,那它返回的 Future 的生命周期就会被这些参数的生命周期所限制:
async fn foo(x: &u8) -> u8 { *x }
// 上面的函数跟下面的函数是等价的:
fn foo_expanded<'a>(x: &'a u8) -> impl Future<Output = u8> + 'a {
async move { *x }
}future的生命周期从'static变为了'a。也就是说 x 必须比 Future 活得更久
在一般情况下,在函数调用后就立即 .await 不会存在任何问题,例如foo(&x).await。但是,若 Future 被先存起来或发送到另一个任务或者线程,就可能存在问题了:
use std::future::Future;
fn bad() -> impl Future<Output = u8> {
let x = 5;
borrow_x(&x) // ERROR: `x` does not live long enough
}
async fn borrow_x(x: &u8) -> u8 { *x }上面的代码在编译时会报错,因为x的在bad执行完的时候就drop了,但是显然Future的生命周期比bad要更久一点。
解决办法如下:
use std::future::Future;
async fn borrow_x(x: &u8) -> u8 { *x }
fn good() -> impl Future<Output = u8> {
async {
let x = 5;
borrow_x(&x).await
}
}如上所示,通过将参数移动到 async 语句块内, 我们将它的生命周期扩展到 'static, 并跟返回的 Future 保持了一致。
注释:这是因为future的默认生命周期就是'static'。
async move
async 允许我们使用 move 关键字来将环境中变量的所有权转移到语句块内,就像闭包那样,好处是你不再发愁该如何解决借用生命周期的问题,坏处就是无法跟其它代码实现对变量的共享:
use futures::{executor::block_on, Future};
// 多个不同的 `async` 语句块可以访问同一个本地变量,只要它们在该变量的作用域内执行
async fn blocks() {
let my_string = "foo".to_string();
let future_one = async {
// ...
println!("{my_string}");
};
let future_two = async {
// ...
println!("{my_string}");
};
// 运行两个 Future 直到完成
let ((), ()) = futures::join!(future_one, future_two);
}
// 由于 `async move` 会捕获环境中的变量,因此只有一个 `async move` 语句块可以访问该变量,
// 但是它也有非常明显的好处: 变量可以转移到返回的 Future 中,不再受借用生命周期的限制
fn move_block() -> impl Future<Output = ()> {
let my_string = "foo".to_string();
async move {
// ...
println!("{my_string}");
}
}
fn main() {
block_on(move_block());
}当.await遇上多线程执行器
需要注意的是,当使用多线程 Future 执行器( executor )时, Future 可能会在线程间被移动,因此 async 语句块中的变量必须要能在线程间传递。 至于 Future 会在线程间移动的原因是:它内部的任何.await都可能导致它被切换到一个新线程上去执行。
由于需要在多线程环境使用,意味着 Rc、 RefCell 、没有实现 Send 的所有权类型、没有实现 Sync 的引用类型,它们都是不安全的,因此无法被使用
需要注意!实际上它们还是有可能被使用的,只要在
.await调用期间,它们没有在作用域范围内。
类似的原因,在 .await 时使用普通的锁也不安全,例如 Mutex 。原因是,它可能会导致线程池被锁:当一个任务获取锁 A 后,若它将线程的控制权还给执行器,然后执行器又调度运行另一个任务,该任务也去尝试获取了锁 A ,结果当前线程会直接卡死,最终陷入死锁中。
因此,为了避免这种情况的发生,我们需要使用 futures 包下的锁 futures::lock 来替代 Mutex 完成任务。
Stream流处理
Stream 特征类似于 Future 特征,但是前者在完成前可以生成多个值,这种行为跟标准库中的 Iterator 特征倒是颇为相似。
关于Stream流的一个常见的例子是消息通道中的消费者Receiver,每次有消息从 Send 端发送后,它都可以接收到一个 Some(val) 值, 一旦 Send 端关闭( drop ),且消息通道中没有消息后,它会接收到一个 None 值。
use futures::{channel::mpsc, executor::block_on, SinkExt, StreamExt};
async fn send_recv() {
const BUFFER_SIZE: usize = 10;
let (mut tx, mut rx) = mpsc::channel::<i32>(BUFFER_SIZE);
tx.send(1).await.unwrap();
tx.send(2).await.unwrap();
drop(tx);
// `StreamExt::next` 类似于 `Iterator::next`, 但是前者返回的不是值,而是一个 `Future<Output = Option<T>>`,
// 因此还需要使用`.await`来获取具体的值
assert_eq!(Some(1), rx.next().await);
assert_eq!(Some(2), rx.next().await);
assert_eq!(None, rx.next().await);
}
fn main() {
block_on(send_recv());
}迭代和并发
跟迭代器类似,我们也可以迭代一个Stream,并且可以使用map,fold,filter等等迭代器可以使用的方法对迭代器的数据进行处理,以及他们遇到错误的提前返回版本:try_map,try_filter,try_fold。
但是跟迭代器又有所不同,for 循环无法在这里使用,但是命令式风格的循环while let是可以用的,同时还可以使用next 和 try_next 方法:
use std::{io, pin::Pin};
use futures::{Stream, StreamExt, TryStreamExt};
async fn sum_with_next(mut stream: Pin<&mut dyn Stream<Item = u32>>) -> u32 {
let mut sum = 0;
while let Some(value) = stream.next().await {
sum += value;
}
sum
}
async fn sum_with_try_next(
mut stream: Pin<&mut dyn Stream<Item = Result<i32, io::Error>>>,
) -> Result<i32, io::Error> {
let mut sum = 0;
while let Some(value) = stream.try_next().await? {
sum += value;
}
Result::Ok(sum)
}上面代码是一次处理一个值的模式,但是需要注意的是:如果你选择一次处理一个值的模式,可能会造成无法并发,这就失去了异步编程的意义。 因此,如果可以的话我们还是要选择从一个 Stream 并发处理多个值的方式,通过 for_each_concurrent 或 try_for_each_concurrent 方法来实现:
use futures::stream::{FuturesUnordered, StreamExt};
// 异步函数,模拟数据处理
async fn process_data(data: i32) -> i32 {
// 假设这里有一些异步处理
data * 2
}
#[tokio::main]
async fn main() {
let data_vec = vec![1, 2, 3, 4, 5];
// 并发处理每个数据项
let futures: FuturesUnordered<_> = data_vec
.into_iter()
.map(|data| process_data(data))
.collect();
futures
.for_each_concurrent(None, |result| async move {
println!("Result: {}", result);
})
.await;
}同时运行多个Future
招数单一,杀伤力惊人,说的就是 .await ,但是光用它,还真做不到一招鲜吃遍天。比如我们该如何同时运行多个任务,而不是使用 .await 慢悠悠地排队完成。
这时候需要祭出我们的大招了,那就是:join!和select!。
join!
futures 包中提供了很多实用的工具,其中一个就是 join! 宏, 它允许我们同时等待多个不同 Future 的完成,且可以并发地运行这些 Future。
先来看一个不是很给力的、使用.await的版本:
async fn enjoy_book_and_music() -> (Book, Music) {
let book = enjoy_book().await;
let music = enjoy_music().await;
(book, music)
}这段代码可以顺利运行,但是有一个很大的问题,就是必须先看完书后,才能听音乐。如何做到边看书边听音乐呢?
我们来试一下futures::join!这个micro:有点像Promise.all这个函数:)
use futures::join;
async fn enjoy_book_and_music() -> (Book, Music) {
let book = enjoy_book().await;
let music = enjoy_music().await;
join!(book, music)
}join!这个micro会返回一个元祖,里面是每一个future执行后返回的值。
如果希望同时运行一个数组里的多个异步任务,可以使用
futures::future::join_all方法
try_join!
由于 join! 必须等待它管理的所有 Future 完成后才能完成,如果你希望在某一个 Future 报错后就立即停止所有 Future 的执行,可以使用 try_join!,特别是当 Future 返回 Result 时:
use futures::try_join;
async fn get_book() -> Result<Book, String> { /* ... */ Ok(Book) }
async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) }
async fn get_book_and_music() -> Result<(Book, Music), String> {
let book_fut = get_book();
let music_fut = get_music();
try_join!(book_fut, music_fut)
}有一点需要注意,传给 try_join! 的所有 Future 都必须拥有相同的错误类型。如果错误类型不同,可以考虑使用来自 futures::future::TryFutureExt 模块的 map_err 和 err_info 方法将错误进行转换:
use futures::{
future::TryFutureExt,
try_join,
};
async fn get_book() -> Result<Book, ()> { /* ... */ Ok(Book) }
async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) }
async fn get_book_and_music() -> Result<(Book, Music), String> {
let book_fut = get_book().map_err(|()| "Unable to get book".to_string());
let music_fut = get_music();
try_join!(book_fut, music_fut)
}join! 很好很强大,但是人无完人,它有一个很大的问题。
select!
join! 只有等所有 Future 结束后,才能集中处理结果,如果你想同时等待多个 Future ,且任何一个 Future 结束后,都可以立即被处理,可以考虑使用 futures::select!:
use futures::{
future::FutureExt, // for `.fuse()`
pin_mut,
select,
};
async fn task_one() { /* ... */ }
async fn task_two() { /* ... */ }
async fn race_tasks() {
let t1 = task_one().fuse();
let t2 = task_two().fuse();
pin_mut!(t1, t2);
select! {
() = t1 => println!("任务1率先完成"),
() = t2 => println!("任务2率先完成"),
}
}一些注意事项:
FutureExt: 这是一个扩展 trait,它为Future类型提供额外的方法。在这里,它被引入是为了使用.fuse()方法,这个方法将来自Futuretrait 的一个 future 转换为一个 “fused” future,即在完成后会继续返回Poll::Ready而不是Poll::Pending。fuse(): 这个方法被调用在task_one()和task_two()的结果上,确保即使 future 在完成后被再次轮询,它也不会产生恐慌。这通常是使用select!宏所必需的,因为select!可能会在一个 future 完成后继续轮询其他的 futures。pin_mut!: 宏用于将 future “钉”(pin)在栈上,这样它们就不能被移动了。在 Rust 中,futures 通常需要被 pin,因为它们的轮询方法要求 self 参数是一个Pin<&mut Self>类型,这确保了 future 在轮询过程中不会被移动。
上面的代码会同时并发地运行 t1 和 t2, 无论两者哪个先完成,都会调用对应的 println! 打印相应的输出,然后函数结束且不会等待另一个任务的完成。
但是,在实际项目中,我们往往需要等待多个任务都完成后,再结束,像上面这种其中一个任务结束就立刻结束的场景着实不多。
default和complete
select!还支持 default 和 complete 分支:
complete分支当所有的Future和Stream完成后才会被执行,它往往配合loop使用,loop用于循环完成所有的Futuredefault分支,若没有任何Future或Stream处于Ready状态, 则该分支会被立即执行
use futures::future;
use futures::select;
pub fn main() {
let mut a_fut = future::ready(4);
let mut b_fut = future::ready(6);
let mut total = 0;
loop {
select! {
a = a_fut => total += a,
b = b_fut => total += b,
complete => break,
default => panic!(), // 该分支永远不会运行,因为 `Future` 会先运行,然后是 `complete`
};
}
assert_eq!(total, 10);
}跟 Unpin 和 FusedFuture 进行交互
首先,.fuse() 方法可以让 Future 实现 FusedFuture 特征, 而 pin_mut! 宏会为 Future 实现 !Unpin 特征,这两个特征恰恰是使用 select 所必须的:
只有实现了 FusedFuture,select 才能配合 loop 一起使用。假如没有实现,就算一个 Future 已经完成了,它依然会被 select 不停的轮询执行。
Unpin,由于select不会通过拿走所有权的方式使用Future,而是通过可变引用的方式去使用,这样当select结束后,该Future若没有被完成,它的所有权还可以继续被其它代码使用。FusedFuture的原因跟上面类似,当Future一旦完成后,那select就不能再对其进行轮询使用。Fuse意味着熔断,相当于Future一旦完成,再次调用poll会直接返回Poll::Pending。
select! 宏用于从多个 Future 中选择一个来执行。由于 a_fut 和 b_fut 都是用 future::ready 创建的,这意味着它们都是立即就绪的。在第一次循环中,select! 宏会随机选择一个就绪的 Future 执行相应的分支。假设它选择了 a_fut,则 total 增加了 a 的值,即 4。
但是,一旦 a_fut 被选择并执行之后,这个 Future 就被认为已经完成了。select! 宏内部使用的逻辑不会再次选择一个已经完成的 Future。这就是为什么在第二次循环中,不会再次选中 a_fut。同理,如果第一次选择了 b_fut,第二次循环将会选择 a_fut。
select! 宏通常与 .fuse() 方法一起使用,以防止一个已经返回 Poll::Ready 的 Future 被再次轮询。
Stream 稍有不同,它们使用的特征是 FusedStream。 通过 .fuse()(也可以手动实现)实现了该特征的 Stream,对其调用 .next() 或 .try_next() 方法可以获取实现了 FusedFuture 特征的Future:
use futures::{
stream::{Stream, StreamExt, FusedStream},
select,
};
async fn add_two_streams(
mut s1: impl Stream<Item = u8> + FusedStream + Unpin,
mut s2: impl Stream<Item = u8> + FusedStream + Unpin,
) -> u8 {
let mut total = 0;
loop {
let item = select! {
x = s1.next() => x,
x = s2.next() => x,
complete => break,
};
if let Some(next_num) = item {
total += next_num;
}
}
total
}在select进行并发
一个很实用但又鲜为人知的函数是 Fuse::terminated() ,可以使用它构建一个空的 Future ,空自然没啥用,但是如果它能在后面再被填充呢?
考虑以下场景:当你要在 select 循环中运行一个任务,但是该任务却是在 select 循环内部创建时,上面的函数就非常好用了。
use futures::{
future::{Fuse, FusedFuture, FutureExt},
stream::{FusedStream, Stream, StreamExt},
pin_mut,
select,
};
async fn get_new_num() -> u8 { /* ... */ 5 }
async fn run_on_new_num(_: u8) { /* ... */ }
async fn run_loop(
mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin,
starting_num: u8,
) {
let run_on_new_num_fut = run_on_new_num(starting_num).fuse();
let get_new_num_fut = Fuse::terminated();
pin_mut!(run_on_new_num_fut, get_new_num_fut);
loop {
select! {
() = interval_timer.select_next_some() => {
// 定时器已结束,若`get_new_num_fut`没有在运行,就创建一个新的
if get_new_num_fut.is_terminated() {
get_new_num_fut.set(get_new_num().fuse());
}
},
new_num = get_new_num_fut => {
// 收到新的数字 -- 创建一个新的`run_on_new_num_fut`并丢弃掉旧的
run_on_new_num_fut.set(run_on_new_num(new_num).fuse());
},
// 运行 `run_on_new_num_fut`
() = run_on_new_num_fut => {},
// 若所有任务都完成,直接 `panic`, 原因是 `interval_timer` 应该连续不断的产生值,而不是结束
//后,执行到 `complete` 分支
complete => panic!("`interval_timer` completed unexpectedly"),
}
}
}当某个 Future 有多个拷贝都需要同时运行时,可以使用 FuturesUnordered 类型。下面的例子跟上个例子大体相似,但是它会将 run_on_new_num_fut 的每一个拷贝都运行到完成,而不是像之前那样一旦创建新的就终止旧的。
use futures::{
future::{Fuse, FusedFuture, FutureExt},
stream::{FusedStream, FuturesUnordered, Stream, StreamExt},
pin_mut,
select,
};
async fn get_new_num() -> u8 { /* ... */ 5 }
async fn run_on_new_num(_: u8) -> u8 { /* ... */ 5 }
// 使用从 `get_new_num` 获取的最新数字 来运行 `run_on_new_num`
//
// 每当计时器结束后,`get_new_num` 就会运行一次,它会立即取消当前正在运行的`run_on_new_num` ,
// 并且使用新返回的值来替换
async fn run_loop(
mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin,
starting_num: u8,
) {
let mut run_on_new_num_futs = FuturesUnordered::new();
run_on_new_num_futs.push(run_on_new_num(starting_num));
let get_new_num_fut = Fuse::terminated();
pin_mut!(get_new_num_fut);
loop {
select! {
() = interval_timer.select_next_some() => {
// 定时器已结束,若 `get_new_num_fut` 没有在运行,就创建一个新的
if get_new_num_fut.is_terminated() {
get_new_num_fut.set(get_new_num().fuse());
}
},
new_num = get_new_num_fut => {
// 收到新的数字 -- 创建一个新的 `run_on_new_num_fut` (并没有像之前的例子那样丢弃掉旧值)
run_on_new_num_futs.push(run_on_new_num(new_num));
},
// 运行 `run_on_new_num_futs`, 并检查是否有已经完成的
res = run_on_new_num_futs.select_next_some() => {
println!("run_on_new_num_fut returned {:?}", res);
},
// 若所有任务都完成,直接 `panic`, 原因是 `interval_timer` 应该连续不断的产生值,而不是结束
//后,执行到 `complete` 分支
complete => panic!("`interval_timer` completed unexpectedly"),
}
}
}